StyleAvatar: Real-time Photo-realistic Portrait Avatar
from a Single Video
Lizhen Wang, Xiaochen Zhao, Jingxiang Sun, Yuxiang Zhang, Hongwen Zhang, Tao Yu, and Yebin Liu
Tsinghua University, NNKOSMOS Technology
SIGGRAPH 2023 Conference
Abstract
Face reenactment methods attempt to restore and re-animate portrait videos as realistically as possible. Existing methods face a dilemma in quality versus controllability: 2D GAN-based methods achieve higher image quality but suffer in fine-grained control of facial attributes compared with 3D counterparts. In this work, we propose StyleAvatar, a real-time photo-realistic portrait avatar reconstruction method using StyleGAN-based networks, which can generate high-fidelity portrait avatars with faithful expression control. We expand the capabilities of StyleGAN by introducing a compositional representation and a sliding window augmentation method, which enable faster convergence and improve translation generalization. Specifically, we divide the portrait scenes into three parts for adaptive adjustments: facial region, non-facial foreground region, and the background. Besides, our network leverages the best of UNet, StyleGAN and time coding for video learning, which enables high-quality video generation. Furthermore, a sliding window augmentation method together with a pre-training strategy are proposed to improve translation generalization and training performance, respectively. The proposed network can converge within two hours while ensuring high image quality and a forward rendering time of only 20 milliseconds. Furthermore, we propose a real-time live system, which further pushes research into applications. Results and experiments demonstrate the superiority of our method in terms of image quality, full portrait video generation, and real-time re-animation compared to existing facial reenactment methods.
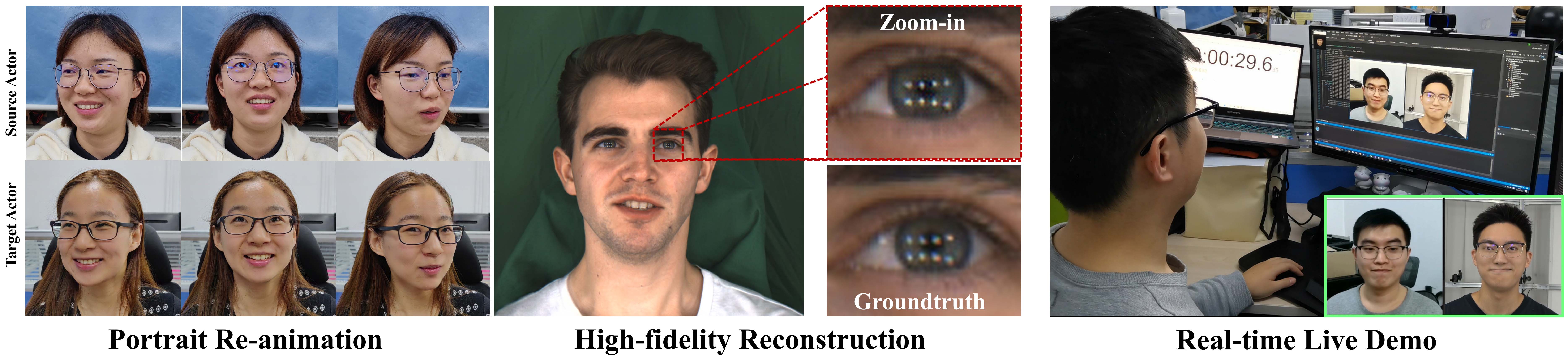
Fig 1. We present StyleAvatar, a real-time high-fidelity portrait avatar from a single video. Our system can run at 35 fps.
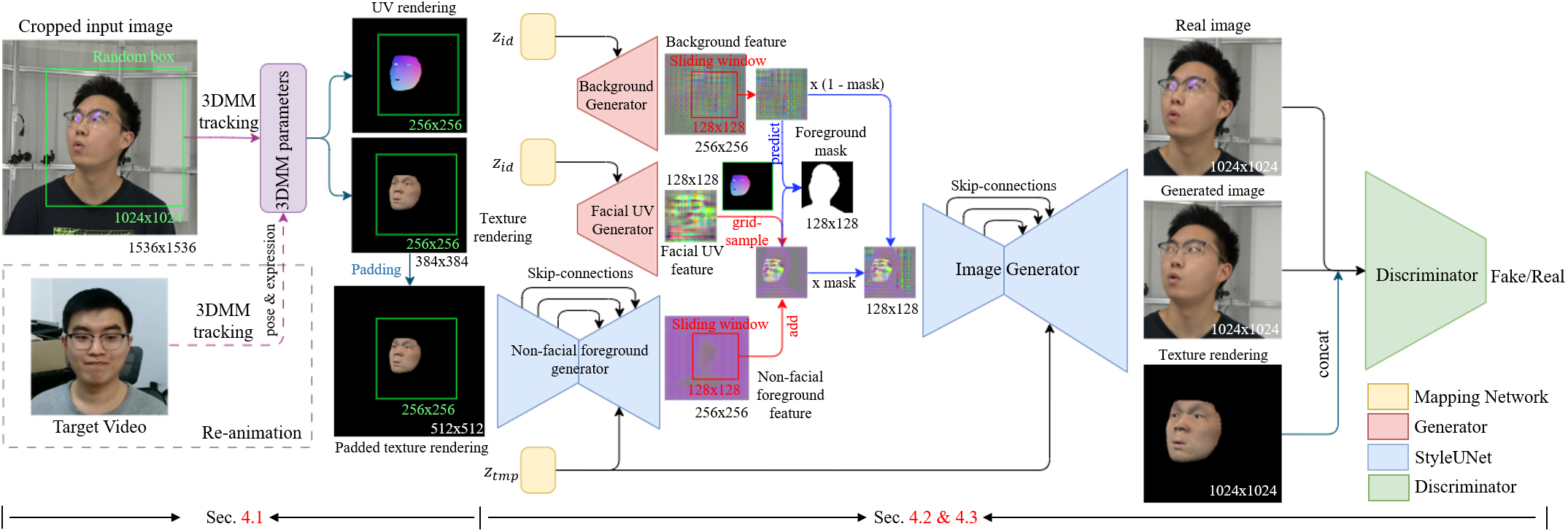
Fig 2. The pipeline of our method.
Results

Fig 3. Facial reenactment results of StyleAvatar.
Technical Paper

Demo Video
Supplimentary Material
See Supplimentary Material for detailed information of the network architecture and more experiments.
Citation
title={StyleAvatar: Real-time Photo-realistic Portrait Avatar from a Single Video},
author={Wang, Lizhen and Zhao, Xiaochen and Sun, Jingxiang and Zhang, Yuxiang and Zhang, Hongwen and Yu, Tao and Liu, Yebin},
booktitle={ACM SIGGRAPH 2023 Conference Proceedings},
pages={},
year={2023}
}
Acknowlegements