IEEE CVPR 2022
Structured Local Radiance Fields for Human Avatar Modeling
Zerong Zheng1, Han Huang2, Tao Yu1, Hongwen Zhang1, Yandong Guo2, Yebin Liu1
1Tsinghua University 2OPPO Research Institute
Abstract
It is extremely challenging to create an animatable clothed human avatar from RGB videos, especially for loose clothes due to the difficulties in motion modeling. To address this problem, we introduce a novel representation on the basis of recent neural scene rendering techniques. The core of our representation is a set of structured local radiance fields, which are anchored to the pre-defined nodes sampled on a statistical human body template. These local radiance fields not only leverage the flexibility of implicit representation in shape and appearance modeling, but also factorize cloth deformations into skeleton motions, node residual translations and the dynamic detail variations inside each individual radiance field. To learn our representation from RGB data and facilitate pose generalization, we propose to learn the node translations and the detail variations in a conditional generative latent space. Overall, our method enables automatic construction of animatable human avatars for various types of clothes without the need for scanning subject-specific templates, and can generate realistic images with dynamic details for novel poses. Experiment show that our method outperforms state-of-the-art methods both qualitatively and quantitatively.
[arXiv] [Dataset]
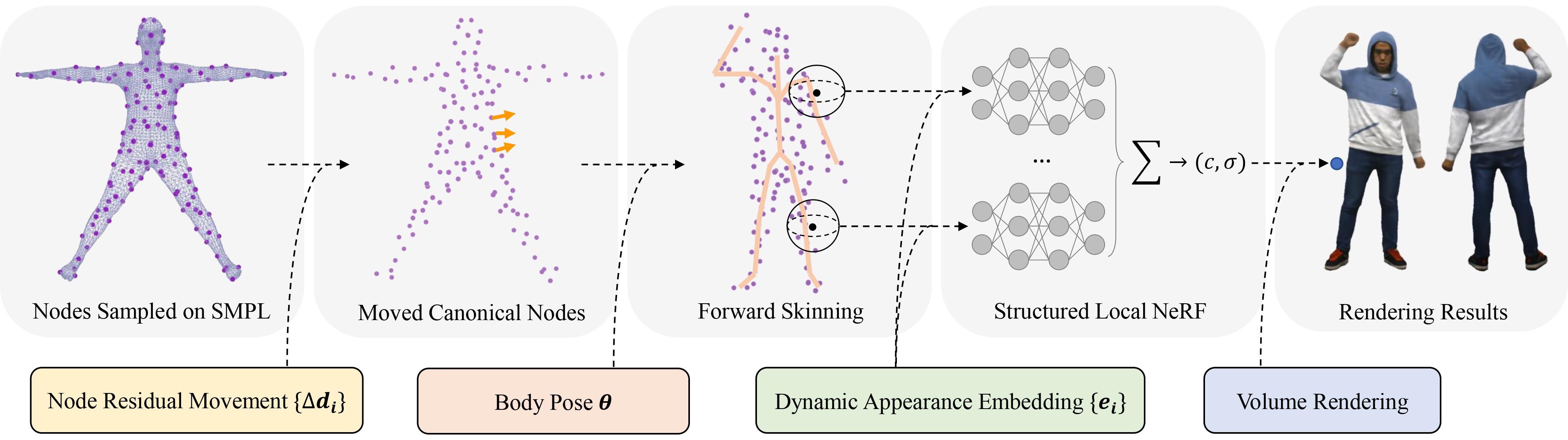
Fig 1. Illustration of our clothed human representation. In our proposed method, we represent the dynamic appearance of a clothed human character using structured local radiance fields attached to pre-defined nodes on the SMPL model. The garment deformations are then modeled in a coarse-to-fine manner with three set of variables, including the body poses as the coarsest level, the node residual translations as the middle level and the dynamic detail embeddings of the local radiance fields as the finest level.
Results

Fig 2. Example results of our method. We train our network on various datasets and show the novel pose synthesis results. Our method not only gracefully tackles different cloth types, but also generates realistic dynamic wrinkles. Please see our supplemental video for more visualization

Fig 3. Example results produced by our method. Our method can learn animatable human avatars with various cloth topologies and realistic dynamic details. Top row: driving video, from which the animation poses are extracted. Bottom two rows: animation results rendered from the front and the back view.
Technical Paper

Demo Video
Citation
Zerong Zheng, Han Huang, Tao Yu, Hongwen Zhang, Yandong Guo, Yebin Liu. "Structured Local Radiance Fields for Human Avatar Modeling". CVPR 2022
@InProceedings{zheng2022structured,
title={Structured Local Radiance Fields for Human Avatar Modeling},
author={Zheng, Zerong and Huang, Han and Yu, Tao and Zhang, Hongwen and Guo, Yandong and Liu, Yebin},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {}
}